The problem with a mismatch in reward and representation
I think this is a beautiful illustration of some interesting knowledge and representation issues in RL. We start with a typical gridworld task with a start state and an end state, and the agent is rewarded for getting to the goal (and is reset to the beginning of the maze).
Here we have a Gridworld maze. The green “G” square is the goal state, where the agent gets reward +1 and has its location reset to the “S” start state. It’s pretty much exploring randomly at this point because the estimated value of each state starts at about the same, a small positive reward.
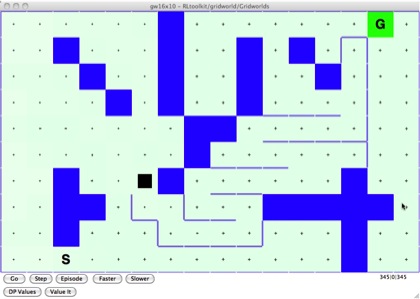
[initial picture]
Then when it finds the goal, there’s an explosion in the value function (this particular agent is using the original Dyna algorithm, which means as it wanders randomly around the world it’s learning which states connect, and besides taking an action each turn it’s updating its evaluation of each state using the model it has learned). You can see the bright green spreading backwards from the goal as it models how those locations lead to the high-reward goal area. There’s a few areas that are near the goal but don’t get updated because it’s never actually seen those states.

[goal discovered]
When this toolkit was originally developed Rich and Steph and I were talking about various ways of extending the basic gridworld so that we could explore some more general learning ideas. “Wouldn’t it be cool”, we said, “if we could add some kind of food reward, if besides the goal state the user could just plop down a piece of pie or a lava spot? Then we could watch how the agent adapted.”
So we did that (well, Steph did all the work). We took our gridworld framework and added in the ability to put spots of reward, that could take any value (positive or negative) and be permanent or consumable (disappear as soon as they’re used).
The consumable reward is indicated by a green pie slice. Putting this into the world means the first time the agent bumps into it, it will get reward +1, but then the reward is “consumed” and disappears. It has to randomly bump into it (it mostly takes the best-looking action but has a small chance of taking a random action, so although the area around the newly-introduced reward has low value eventually the agent will bump into it).
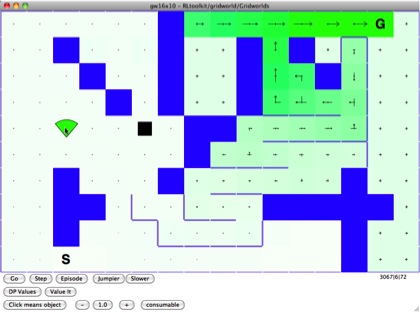
[consumable reward introduced]
Once it finds the reward, we see the same explosion in value that we saw when it found the goal state. The problem is that this was a one-time thing. The reward was consumed, but the agent frantically searches around where it used to be. It can only “know” about the location-transitions and reward of each state, so it has no way of representing that the reward disappeared. “This was a good place. Other places that lead to that good place must be good.”

[consumable reward consumed]
The agent jitters around that area until the value function is sufficiently depressed, and then go back to its mostly straightforward path from start to goal.

[value function lowered]
And there’s the problem with just plopping reward in. The agent has absolutely no way of representing “it was here and now it’s not” because it doesn’t actually represent “it” or “here” or anything but the state transitions and the value. The observation is a location label—as far as the agent is concerned this one time it got reward in state 783, and then it didn’t. There is no room in the strict model to understand consumable rewards.
So there we have a dead-simple, canonical example of why there’s work to be done on understanding knowledge representation in RL. Once you see it happen, it makes sense—of course it was naive to think the agent could deal with consumable rewards without any representation of timing or transience or structure beyond the state label. In retrospect, it makes perfect sense. But how often are we repeating the same naive mistake in more complicated settings, asking an agent to make distinctions that it simply cannot represent? That’s a fundamental question I’m interesting in researching.
Video:
